
ISY Summer of Code 2022
Posted 2022-08-16 by Gustav Sörnäs
This summer I've had the opportunity to work in a Summer of Code organized by the department of Electrical Engineering (ISY) at Linköping University. This post will summarize a few of the changes I worked on and had particularly fun with.
Background🔗
I was selected to work half-time for two
months on Spade, but I had a lot of freedom in what exactly I did.
A complete listing of all merged merge requests (at least in the spade-lang
Gitlab organization, so not counting e.g. prr) can be found on
Gitlab
(from spade!75 and onwards). Apart from that I also helped review some merge
requests (also on
Gitlab).
You can read more about Spade on the main Spade website. Spade, as well as most of the tooling, is implemented in Rust, so some of the content here will also touch on Rust.
About me🔗
Before I started university, I had not done any hardware programming (or hardware anything really, apart from building my desktop computer) at all. University introduced me first to digital electronics using physical wires and later to VHDL and hardware programming.
I had already been contributing to Spade for a couple of months, and I had used it twice in game jam projects. (Not really the intended use case but it worked out alright.) Still, I wouldn't call myself a expert in hardware by any means. What's nice about a hardware compiler is that I usually don't have to worry that much about the actual hardware going on since the compiler hides most of the weirdness behind abstractions. I could for example work on the parser without worrying at all about Verilog.
Tracing in the compiler🔗
As a first task, I wanted to get a better feel for the Spade compiler structure.
We had specialized tracing (logging) for the parser and typechecker, but I
wanted something more like the tracing found in the Rust
compiler. It turns out Rust
uses public libraries (tracing,
"scoped, structured logging and diagnostics", and
tracing-tree for the output) so
we could add them right away.
Adding tracing and tracing-tree was first done in
spade!75. We opted to
not add the tracing events themselves all at once since the compiler is too
large for that. Instead, we added them as needed when we worked on fixing other
bugs.
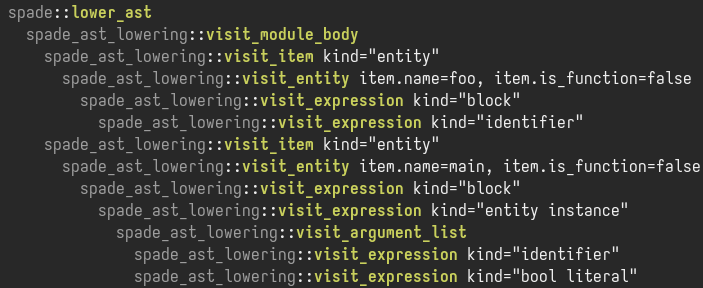
Example of tracing output for the AST lowering stage.
We still have two old systems that can annotate functions and show a tree-like view of the program flow (for parsing and type checking) which are left for now. At some point they could probably be incorporated into tracing.
Multipart suggestions🔗
One important goal of the Spade compiler is to be friendly to humans. Here's an example error message from a small fix I did in spade!94:
error: Multiple definitions of b
┌─ testinput:1:8
│
1 │ entity b() -> bool {
│ ^ Multiple items named b
·
5 │ use x::b;
│ ---- Previous definition here
A Spade compiler error example
This can be compared with the output for the equivalent error (two entities with the same name) when compiling some VHDL in one of my university courses, using a to-be-unnamed proprietary compiler.
=========================================================================
* HDL Parsing *
=========================================================================
Parsing VHDL file "/home/user/..../lab.vhd" into library work
Parsing entity <lab>.
Parsing entity <lab>.
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 13: <std_logic> is not declared.
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 14: <unsigned> is not declared.
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 15: <unsigned> is not declared.
ERROR:HDLCompiler:854 - "/home/user/..../lab.vhd" Line 12: Unit <lab> ignored due to previous errors.
Parsing architecture <Behavioral> of entity <lab>.
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 51: <rx> is not declared.
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 47: <rst> is not declared.
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 46: Type error near clk ; current type unsigned; expected type std_ulogic
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 69: <rst> is not declared.
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 68: Type error near clk ; current type unsigned; expected type std_ulogic
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 102: <rst> is not declared.
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 101: Type error near clk ; current type unsigned; expected type std_ulogic
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 130: <rst> is not declared.
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 129: Type error near clk ; current type unsigned; expected type std_ulogic
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 148: <rst> is not declared.
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 147: Type error near clk ; current type unsigned; expected type std_ulogic
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 171: <rst> is not declared.
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 170: Type error near clk ; current type unsigned; expected type std_ulogic
ERROR:HDLCompiler:1728 - "/home/user/..../lab.vhd" Line 192: Type error near clk ; current type unsigned; expected type std_logic
ERROR:HDLCompiler:69 - "/home/user/..../lab.vhd" Line 192: <rst> is not declared.
Sorry, too many errors..
-->
A VHDL compiler error example. Too many errors indeed.
We use a library called codespan which renders
our source code annotated with labels that can point to different spans, as seen
above. Before the Summer of Code we had already implemented support for
suggestions in which we attach suggestions to error messages. These suggestions
consist of a span to remove and a text to replace it with. What's nice is that
all combinations of add and remove (only addition, only removal, and
replacement) could be chosen by leaving either the span or the text empty.
error: Expected array size
┌─ testinput:2:12
│
2 │ let _: [bool] = [true, false];
│ ^^^^^^ This array type
│
= Array types need a specified size
= Insert a size here
│
2 │ let _: [bool; N] = [true, false];
│ +++
An example of a suggestion with a single replacement. In this
case, the replacement span is the empty span between l and ], and the
replacement text is ; N.
In codespan!2, I then added support for suggestions that consist of multiple parts.
error: Unexpected `(`, expected `{`, `,`, or `}`
┌─ main.spade:2:6
│
2 │ B(n: int<4>),
│ ^ expected `{`, `,`, or `}`
│
= Use `{` if you want to add items to this enum variant
│
2 │ B{n: int<4>},
│ ~ ~
An example of a suggestion with multiple replacements.
There is still work left to do. For starters, suggestions currently need to be on the same line to be rendered.
error: Unexpected `(`, expected `{`, `,`, or `}`
┌─ main.spade:2:6
│
2 │ B(
│ ^ expected `{`, `,`, or `}`
│
= (Note: skipped showing 1 multi-line suggestion)
An example of a suggestion over multiple lines that is skipped.
At some point we also probably want to upstream this into the original codespan repository.
Board presets in Swim configurations🔗
In addition to Spade, we also have a build tool called Swim. It handles some of the work in getting your Spade code programmed onto an FPGA. It does this through a series of steps.
- Build
- Synthesis
- Place and route
- Packing
- Uploading
Since FPGA models have unique hardware characteristics, we need to specify different values and programs for different boards in a Swim configuration file. Here's how it looks for the Go Board I have at home.
compiler_dir = "spade"
[synthesis]
top = "top"
extra_verilog = ["src/top.v"]
command = "synth_ice40"
[pnr]
architecture = "ice40"
device = "iCE40HX1K"
pin_file = "go.pcf"
package = "vq100"
[packing]
tool = "icepack"
[upload]
tool = "iceprog"
Example Swim.toml for the Go Board FPGA.
Compare this to the configuration required for the ECPIX-5. Notably, [pnr],
[upload] and [packing] contains completely different values.
compiler_dir = "spade"
[synthesis]
top = "top"
extra_verilog = [ "src/top.v" ]
command = "synth_ecp5"
[pnr]
architecture = "ecp5"
device = "LFE5UM5G-45F"
pin_file = "ecpix5.lpf"
package = "CABGA554"
[upload]
tool = "openocd"
config_file = "openocd-ecpix5.cfg"
[packing]
tool = "ecppack"
idcode = "0x81112043"
Example Swim.toml for the ECPIX-5 FPGA.
Now, most of this configuration will be the same for each Go Board, or ECPIX-5,
or insert your FPGA of choice here. So in
swim!26 I added
support for a [board]-directive in the configuration file. You could then instead of the
above configurations write:
compiler_dir = "spade"
[synthesis]
top = "top"
extra_verilog = ["src/top.v"]
command = "synth_ice40"
[board]
name = "go-board"
pcf = "go.pcf"
Example Swim.toml for the Go Board FPGA, with [board].
compiler_dir = "spade"
[synthesis]
top = "top"
extra_verilog = [ "src/top.v" ]
command = "synth_ecp5"
[board]
name = "ecpix-5"
pin_file = "ecpix5.lpf"
config_file = "openocd-ecpix5.cfg"
Example Swim.toml for the ECPIX-5 FPGA, with [board].
The fields pin_file and pcf are used to map pins on the board to input and output
signals in the code, which means it is not the same from project to project and
therefore still specified.
Lock file for "pinning" dependencies in Swim🔗
Before the Summer of Code, we had already added support for dependencies in Swim.
compiler_dir = "spade"
[libraries.my-dependency]
git = "https://example.com/git/repository.git
branch = "main"
Example dependency in a Swim configuration file
When you run swim build for the first time, Swim will fetch a copy of the
repository, checkout the specified branch and build it as a separate module.
After the first build, Swim won't re-fetch the repository unless you run swim update (so you don't have to have an internet connection ever time you build).
But if you later build this project on another computer, what happens if the
branch has been updated in the repository? To ensure the project uses the same
dependencies, we create a file swim.lock containing the hash of the commit
which takes priority over the specified reference in swim.toml. (It's a bit
hard to exemplify but you might be aware of lock files from other build tools
like Cargo, npm and Nix (flakes).)
The hardest part about this change wasn't the actual change, but testing it.
What good is a complex feature like this if you can't trust that it even works
from the start? Most of Swim relied on relative paths and changing the active
directory (like cd) which in combination with tests running in parallel made
the test suite more racy than an F1 GP. The solution was to not have
relative paths and tests that all change the active directory, by instead
making all paths absolute paths instead.
What's more, the logging output was
not captured by the test suite, so it all went to the same terminal, making it
borderline impossible to debug where stuff went wrong. (Usually, Cargo collects
output from tests and only prints it per test for failed tests. The solution was
to wrap the log call in a println with fern::Output::call(|record| println!("{}", record.args()));.) My misery can
be found in swim!37.
This also came during the worst of the summer heat, and I got to experience first-hand the loss of productivity when it's 30+°C degrees outside and somewhere around 25-28 °C inside for an entire week.
Gitlab CI🔗
Speaking of tests, I found myself debugging CI pipelines at multiple points for different projects. I've created new CI configurations for our mdbook, this blog and our codespan fork. We also have a tool called Trawler that tries to build a list of projects to ensure we don't accidentally break "real" code (and as an incentive to keep a couple of external projects up-to-date), so for that I wrote a JUnit-generator since Gitlab understands and renders JUnit-reports.
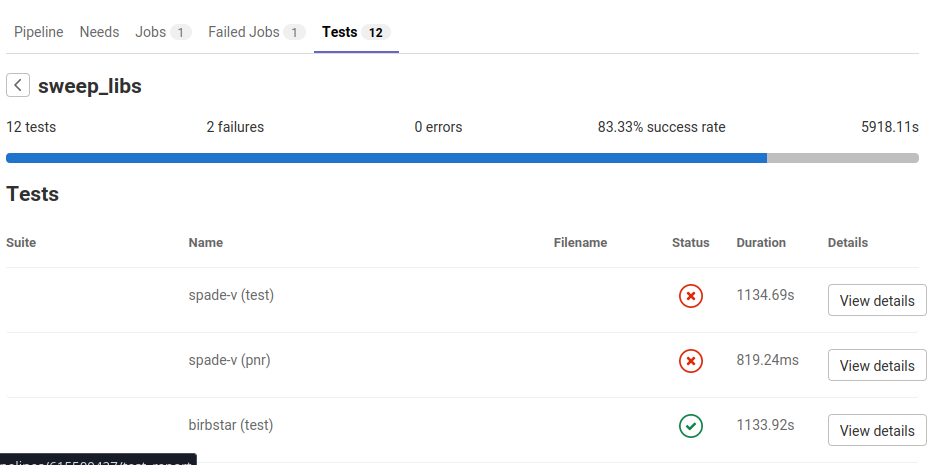
A Trawler JUnit report on Gitlab.
This blog🔗
Towards the end of the summer we felt like it would be nice to write a bit about what I had done and how everything had went. Thus, this blog. I started with a scrapped personal website and modified the look to be more like the main spade-lang.org. You're browsing the result right now :).
I've been getting used to Zola more and more, but some things are still a bit difficult to do (and more importantly, not really documented). I have collected an example in the appendix. Still, right when I want to give up and make an ugly hack in the Zola source, a solution usually presents itself.
Gitlab support for prr for offline code reviews🔗
During development I found a tool called prr.
From the repository:
prris a tool that brings mailing list style code reviews to Github PRs. This means offline reviews and inline comments, more or less.
I had found myself on quite a few train rides without internet access, so this
sounded like something I could use. I had gotten permission to work a bit on
unrelated tooling if it was to help me work on Spade, and since we use
Gitlab instead of Github I got to work on adding Gitlab support. This didn't
take too long (a day or two) since I had already used the
gitlab-crate for doing API calls to Gitlab
before.
The resulting fork can be found on Github. It doesn't support spanned comments due to some funky API documentation.
Appendix A: Zola workaround example🔗
In Zola, the special variables page and section aren't inherited when using
include "something.html" (I think). So here's a weird solution to work around
that:
We want the header link (top left) to link to
1) If we're rendering a post, the containing section.
2) If we're rendering a section, this section.
3) If we're rendering the homepage, the homepage.
[[ templates/base.html ]]
{% if page %}
{% set this = page %}
{% set page = page %}
{% elif section %}
{% set this = section %}
{% set section = section %}
{% endif %}
[[ templates/partials/nav.html (included from
templates/base.html) ]]
{% if page %}
{% set section = get_section(path=page.ancestors | last) %}
<a href={{ section.permalink }}>
{{ section.title | default(value=config.title) }}
</a>
{% elif section and section.title %}
{{ section.title }}
{% else %}
{{ config.title }}
{% endif %}
Appendix B: Spanned comments using the Gitlab API🔗
While working on spanned comments (comments that target a line range instead of
a single line) I had a """fun""" problem with the API documentation. There is a
header in the documentation called Create a new merge request
thread
which shows us how to create a thread pointing to a single line. Great! Let's
use it. We use the already existing code to take a review file and parse it into
a list of InlineComment. Then, we use an iterator and map (transform, sort
of) each inline comment into its own thread.
(This code is simplified to make a point. Check the original if you're interested.)
let discussions = inline_comments
.iter()
.map(|c| {
let mut position = Position::new();
match c.line {
// Since we're commenting on a diff, all of these
// contain two values: the line number the comment
// is at before and after the diff is applied.
LineLocation::Removed(old_line, _) => {
position.old_line(old_line);
}
LineLocation::Added(_, new_line) => {
position.new_line(new_line);
}
// Fun fact: having both old_line and new_line here
// is mandated by the API.
LineLocation::Changed(old_line, new_line) => {
position.old_line(old_line).new_line(new_line);
}
}
CreateMergeRequestDiscussion::new()
.body(&c.comment)
.position(position)
});
Adding comments on single lines on Gitlab (simplified).
If you're not used to builders and/or Rust this might look a bit odd but the
point is that each InlineComment is turned into a
CreateMergeRequestDiscussion with a body and position. Both of those are
mapped from the InlineComment without much trouble.
Let's try to apply this to spanned comments. The API (Parameters for multiline comments) tells us that we need a line code and type for the start and end of each comment. The line code is documented right below this header and combines the hash of the file we're commenting on, the line number before the change and the line number after the change. This is information we have, so it should be fine. The API also wants a "type" and I quote:
- Attribute:
position[line_range][start][type]- Type: string
- Required: yes
- Description: "Use
newfor lines added by this commit, otherwiseold"
Since our chosen API wrapper is well made it mirrors this. Well, I tried implementing it, but it didn't work. It's a bit difficult to debug since the comments still show up as normal single line comments. I did however compare the request that is sent (top) with the one sent when using Gitlabs own web UI (bottom):
line_range: Some(
LineRange {
start: LineCode {
line_code: "1b[...]b7_12_10",
type_: Old,
},
end: LineCode {
line_code: "1b[...]b7_15_14",
type_: Old,
},
}
)
"line_range":{
"start":{
"line_code":"1b[...]b7_12_10",
"type":null,
"old_line":12,
"new_line":10
},
"end":{
"line_code":"1b[...]b7_15_14",
"type":null,
"old_line":15,
"new_line":14
}
}
What should be the same comment. Comparison between my prr-fork (top) and the Gitlab web-UI (bottom).
Interestingly, we see that Gitlab:
- Sets
typetonulleven though it should be a string that is either"old"or"new"according to the documentation. - Sets
old_lineandnew_lineonline_range[start]andline_range[end], fields that don't exist in the documentation. They're also duplicated from information that is already present in the line code.
Maybe there is a way to "bypass" the type system and modify the API calls with custom fields? In any case, I've given up on spanned comments for now since single line comments look almost exactly the same. If you have any ideas, feel free to drop by the forked repo at sornas/prr (github).